
Having talked about different kinds of memory, now it's time to dive into how these are created at Volary, and how that gives rise to useful feedback for agents. There are multiple steps in the process to go from a running agent to re-injecting memories on later runs.
Episodes
The agent's transcripts are run through the Volary system. In the usual case this is with Volary acting as a proxy to the upstream LLM provider, which is the simplest setup and the most powerful. Not all coding agents support this though, so in those cases we install lifecycle hooks to upload transcripts at the completion of an agentic loop.
From these transcripts, Volary extracts a series of episodes. These episodes are sequences of messages within a conversation; they may involve back-and-forth with the user, or they may be a sequence of agent actions which imply something interesting happened (for example, a failed tool call which it later corrected). These are surfaced in the web UI for curious users:
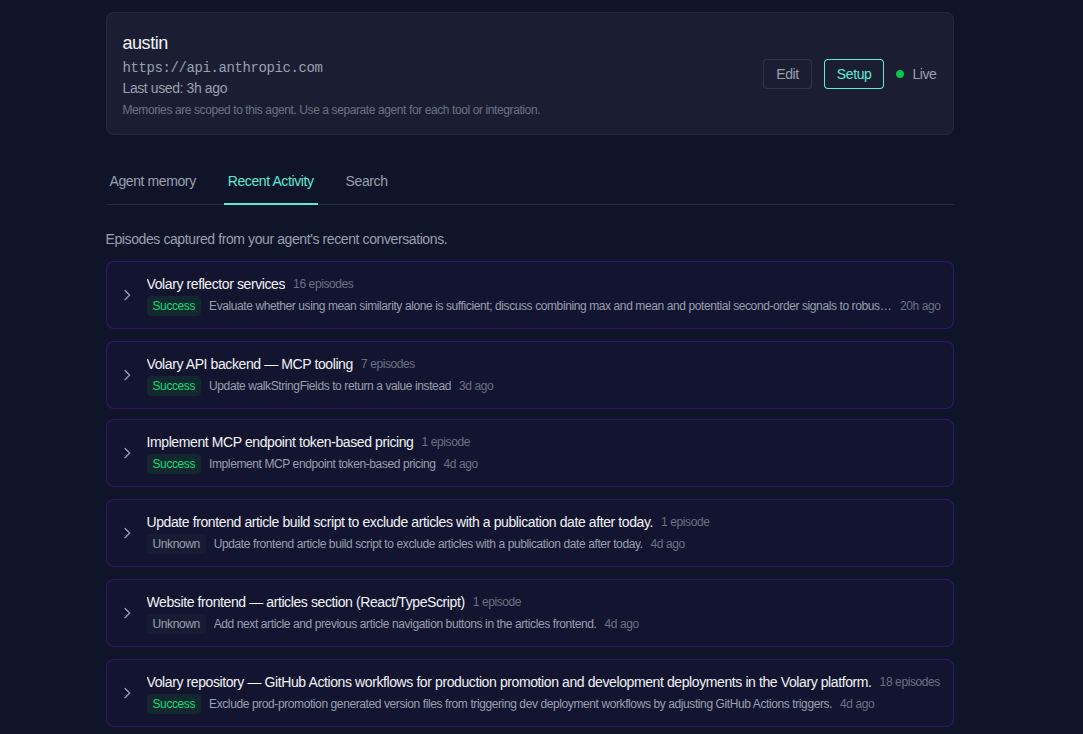
As you can see here, episodes are also grouped with one another in cases where they are similar. This becomes important as we go on to process them further.
These episodes form (unsurprisingly) episodic memory, which you'll remember us discussing in the last article. On their own they are potentially of some use - agents can explore them and learn about things they have done in the past, what worked and what didn't - but they are also a fairly unwieldy way of learning that. They are a critical foundation to build further memories on; thinking about how our own memories work, we don't think back through the process of learning to drive a car when we remember how to do it, but if we think we can still connect that knowledge back to when we learned it.
Reflections
The next step is to derive reflections from these episodes. After new episodes are created, a subsequent process runs over them to look for new memories that can be learned. Ideally there will be multiple episodes supporting a new reflection, but if it's sufficiently clear what has happened and the consequence of it then a reflection can be created from just a single episode.
It's also possible that the episode might correspond to existing reflections, in which case it is merged into them; it may simply take the form of additional evidence for it, but it can also change and expand the reflection if it adds quality new information. This is also the point where episodes can contradict existing reflections, and they may need to be deleted because they no longer reflect reality (because the project conventions have changed, the tech stack is different now, or the world has moved on).
Indexing
Just having created these reflections isn't enough. The agent needs to be able to find them - to facilitate this we create indexes around them which group reflections and link them together. The most obvious form is via a general 'recall' tool where the agent can supply descriptions of what it wants. This is a way for it to remember things that it thinks are relevant, which can be helpful - but often it is hard for the agent to describe sufficiently accurately what it wants to look for, or it doesn't think to ask on a particular topic that might have been helpful.
The solution we found to this was to build a top-level index for each agent which is kept up-to-date as reflections change. This is a bit like being presented with a menu at a restaurant - it might contain an item that is exactly what you felt like when you came in. Or, maybe there is a moment of serendipity and you see something that you wouldn't have thought of having, but now you've seen it, you really want to know what it's like.
Beneath this, an index is maintained against each reflection of other reflections that are near to it in memory space - either they are similar, or they relate to similar episodes, etc. As a result, memories are linked together into a graph, which agents are free to explore as they need; it's not often that they need to explore extremely deeply but the option is there.
Retrieval
Finally, reflections are available for the agent to retrieve. This is done by a set of MCP tools, which let the agent recall
specific episodes or reflections, or try to recall more generally. Finally, there is a remember tool that the agent can use
if it very specifically wants to remember something (e.g. if the user explicitly prompts it "remember that for next time"),
which adds it to the episode extraction / reflection process specifically.
This then happens inline with the agent, without the user having to do anything else during their interactions. Once some reflections have been built up, they appear in future conversations, informing the agent and improving its performance:
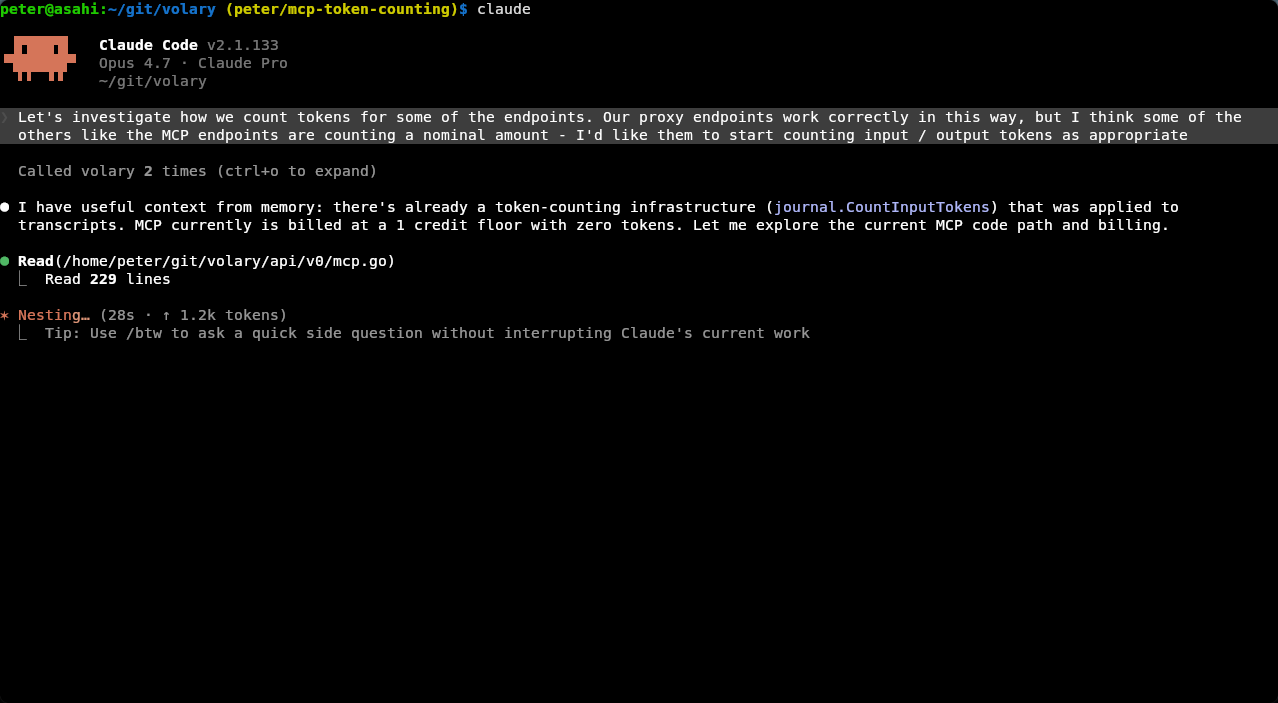
The outcome of this is an agent that is more knowledgeable and smarter. They're able to learn from experience and each day isn't their first day on the job any more.
We're super excited about the possibilities here. If you're interested in learning more, just try it out!